
3 Ways to Build ETL Process Pipelines with Examples [2024 Updated]
Are you stuck in the past? Are you still using the slow and old-fashioned Extract, Transform, Load (ETL) paradigm to process data? Do you wish there were more straightforward and faster methods out there?
Well, wish no longer! In this article, we’ll show you how to implement two of the most cutting-edge data management techniques that provide huge time, money, and efficiency gains over the traditional Extract, Transform, Load model.
One such method is stream processing that lets you deal with real-time data on the fly. The other is automated data management that bypasses traditional ETL and uses the Extract, Load, Transform (ELT) paradigm. For the former, we’ll use Kafka, and for the latter, we’ll use Panoply’s data management platform.
But first, let’s give you a benchmark to work with: the conventional and cumbersome Extract Transform Load process.
What is ETL (Extract Transform Load)?
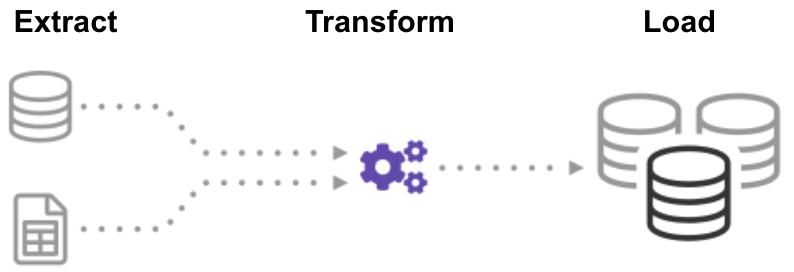
ETL (Extract, Transform, Load) is an automated process which takes raw data, extracts the information required for analysis, transforms it into a format that can serve business needs, and loads it to a data warehouse. ETL typically summarizes data to reduce its size and improve performance for specific types of analysis.
When you build an ETL infrastructure, you must first integrate data from a variety of sources. Then you must carefully plan and test to ensure you transform the data correctly. This process is complicated and time-consuming.
Let’s start by looking at how to do this the traditional way: batch processing.
1. Building an ETL Pipeline with Batch Processing
In a traditional ETL pipeline, you process data in batches from source databases to a data warehouse. It’s challenging to build an enterprise ETL workflow from scratch, so you typically rely on ETL tools such as Stitch or Blendo, which simplify and automate much of the process.
To build an ETL pipeline with batch processing, you need to:
- Create reference data: create a dataset that defines the set of permissible values your data may contain. For example, in a country data field, specify the list of country codes allowed.
- Extract data from different sources: the basis for the success of subsequent ETL steps is to extract data correctly. Take data from a range of sources, such as APIs, non/relational databases, XML, JSON, CSV files, and convert it into a single format for standardized processing.
- Validate data: Keep data that have values in the expected ranges and reject any that do not. For example, if you only want dates from the last year, reject any values older than 12 months. Analyze rejected records, on an on-going basis, to identify issues, correct the source data, and modify the extraction process to resolve the problem in future batches.
- Transform data: Remove duplicate data (cleaning), apply business rules, check data integrity (ensure that data has not been corrupted or lost), and create aggregates as necessary. For example, if you want to analyze revenue, you can summarize the dollar amount of invoices into a daily or monthly total. You need to program numerous functions to transform the data automatically.
- Stage data: You do not typically load transformed data directly into the target data warehouse. Instead, data first enters a staging database which makes it easier to roll back if something goes wrong. At this point, you can also generate audit reports for regulatory compliance, or diagnose and repair data problems.
- Publish to your data warehouse: Load data to the target tables. Some data warehouses overwrite existing information whenever the ETL pipeline loads a new batch - this might happen daily, weekly, or monthly. In other cases, the ETL workflow can add data without overwriting, including a timestamp to indicate it is new. You must do this carefully to prevent the data warehouse from “exploding” due to disk space and performance limitations.
2. Building an ETL Pipeline with Stream Processing
Modern data processes often include real-time data, such as web analytics data from a large e-commerce website. In these cases, you cannot extract and transform data in large batches but instead, need to perform ETL on data streams. Thus, as client applications write data to the data source, you need to clean and transform it while it’s in transit to the target data store.
Many stream processing tools are available today - including Apache Samza, Apache Storm, and Apache Kafka. The diagram below illustrates an ETL pipeline based on Kafka, described by Confluent:
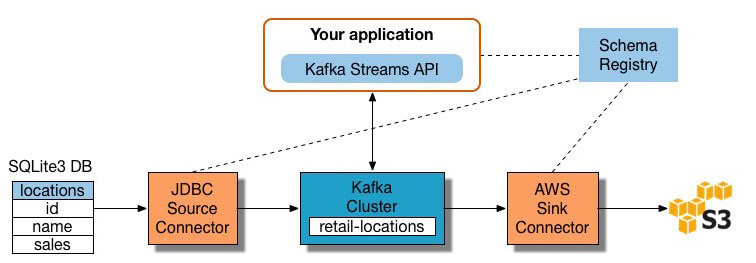
To build a stream processing ETL pipeline with Kafka, you need to:
- Extract data into Kafka: the Confluent JDBC connector pulls each row of the source table and writes it as a key/value pair into a Kafka topic (a feed where records are stored and published). Applications interested in the state of this table read from this topic. As client applications add rows to the source table, Kafka automatically writes them as new messages to the Kafka topic, enabling a real-time data stream. Note you can implement a database connection yourself without Confluent’s commercial product.
- Pull data from Kafka topics: the ETL application extracts messages from the Kafka topic as Avro records, creates an Avro schema file, and deserializes them. Then it creates KStream objects from the messages.
- Transform data in KStream objects: with the Kafka Streams API, the stream processor receives one record at a time, processes it, and produces one or more output records for downstream processors. These processors can transform messages one at a time, filter them based on conditions, and perform data operations on multiple messages such as aggregation.
- Load data to other systems: the ETL application still holds the enriched data, and now needs to stream it into target systems, such as a data warehouse or data lake. In Confluent’s example, they propose using their S3 Sink Connector to stream the data to Amazon S3. You can also integrate with other systems such as a Redshift data warehouse using Amazon Kinesis.
Now you know how to perform ETL processes the traditional way and for streaming data. Let’s look at the process that is revolutionizing data processing: Extract Load Transform.
What is ELT (Extract Load Transform)?
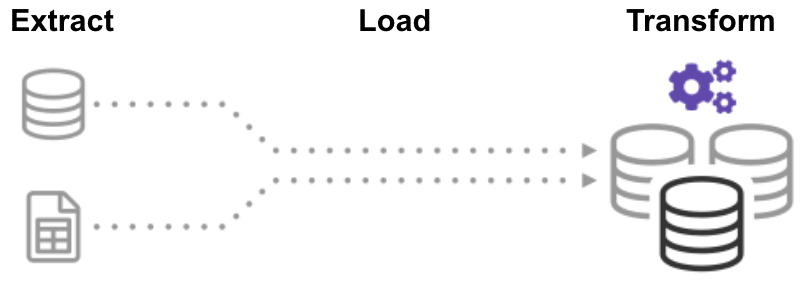
In the Extract Load Transform (ELT) process, you first extract the data, and then you immediately move it into a centralized data repository. After that, data is transformed as needed for downstream use. This method gets data in front of analysts much faster than ETL while simultaneously simplifying the architecture.
Moreover, today’s cloud data warehouse and data lake infrastructure support ample storage and scalable computing power. Thus, it’s no longer necessary to prevent the data warehouse from “exploding” by keeping data small and summarized through transformations before loading. It’s possible to maintain massive data pools in the cloud at a low cost while leveraging ELT tools to speed up and simplify data processing.
ELT may sound too good to be true, but trust us, it’s not! Let’s build an automated ELT pipeline now.
3. Building a Pipeline without ETL Using an Automated Cloud Data Warehouse
New cloud data warehouse technology makes it possible to achieve the original ETL goal without building an ETL system at all.
For example, Panoply’s automated cloud data warehouse has end-to-end data management built-in. Panoply has a ton of native data source integrations, including CRMs, analytics systems, databases, social and advertising platforms, and it connects to all major BI tools and analytical notebooks.
To build a data pipeline without ETL in Panoply, you need to:
-
Select data sources and import data: select data sources from a list, enter your credentials and define destination tables. Click “Collect,” and Panoply automatically pulls the data for you. Panoply automatically takes care of schemas, data preparation, data cleaning, and more.
- Run transformation queries: select a table and run an SQL query against the raw data. You can save the query as a transformation, or export the resulting table as a CSV. You can run several transformations until you achieve the data format you need. You shouldn’t be concerned about “ruining” the data - Panoply lets you perform any transformation, but keeps your raw data intact.
- Perform data analysis with BI tools: you can now connect any BI tool such as Tableau or Looker to Panoply and explore the transformed data.
The above process is agile and flexible, allowing you to quickly load data, transform it into a useful form, and perform analysis. For more details, see Getting Started with Panoply.
Out with the Old, in with the New
You now know three ways to build an Extract Transform Load process, which you can think of as three stages in the evolution of ETL:
- Traditional ETL batch processing - meticulously preparing and transforming data using a rigid, structured process.
- ETL with stream processing - using a modern stream processing framework like Kafka, you pull data in real-time from source, manipulate it on the fly using Kafka’s Stream API, and load it to a target system such as Amazon Redshift.
- Automated data pipeline without ETL - use Panoply’s automated data pipelines, to pull data from multiple sources, automatically prep it without requiring a full ETL process, and immediately begin analyzing it using your favorite BI tools. Get started with Panoply in minutes.
Traditional ETL works, but it is slow and fast becoming out-of-date. If you want your company to maximize the value it extracts from its data, it’s time for a new ETL workflow.
Panoply is a secure place to store, sync, and access all your business data. Panoply can be set up in minutes, requires minimal on-going maintenance, and provides online support, including access to experienced data architects. Free 21-Day Proof of Value.